4 Essential Helicone Features to Optimize Your AI App's Performance
Introduction
Helicone empowers AI engineers and LLM developers to optimize their applications’ performance. This guide provides step-by-step instructions for integrating and making the most of Helicone’s features — available on all Helicone plans.
This blog post is for you if:
- You’re building or maintaining an AI application
- You need to improve response times, reduce costs, or enhance reliability
- You want data-driven insights to guide your optimization efforts
- You’re looking for practical, implementable solutions
We will focus on the 4 essential Helicone features: custom properties, sessions, prompts, and caching, how each feature works, why it matters, and how to implement it in your development workflow.
If you’re ready to follow the practical steps with zero fluff, read on.
Getting started: integrating with 1-line of code
Whether you’re prototyping or maintaining a production app, Helicone’s one-line integration lets you focus on building, not configuring.
Integrating with any provider
-
Change a single line of code to integrate Helicone with your AI app.
-
Compatible with various AI models and APIs. Here’s the entire list of integrations.
-
Update the base URL to easily switch between models (e.g., GPT-4 to LLaMA).
# Before baseURL = "https://api.openai.com/v1" # After baseURL = "https://oai.helicone.ai/v1"
#1: Custom properties: segmenting your requests
Custom Properties helps you tailor the LLM analytics to your needs. Custom Properties lets you segment requests, allowing you to make more data-driven improvements and targeted optimizations.
In a nutshell
- Custom Properties can be implemented using headers
- Custom Properties supports any type of custom metadata
How it works
-
Add custom headers to your requests using this format:
Helicone-Property-[Name]: [value]whereNameis the name of your custom property. For example:headers = { "Helicone-Property-Session": "121", "Helicone-Property-App": "mobile", "Helicone-Property-Conversation": "support_issue_2" }More info about Custom Properties in the docs.
-
Now you can segment incoming requests on the Dashboard, Requests, or Properties page. For example:
-
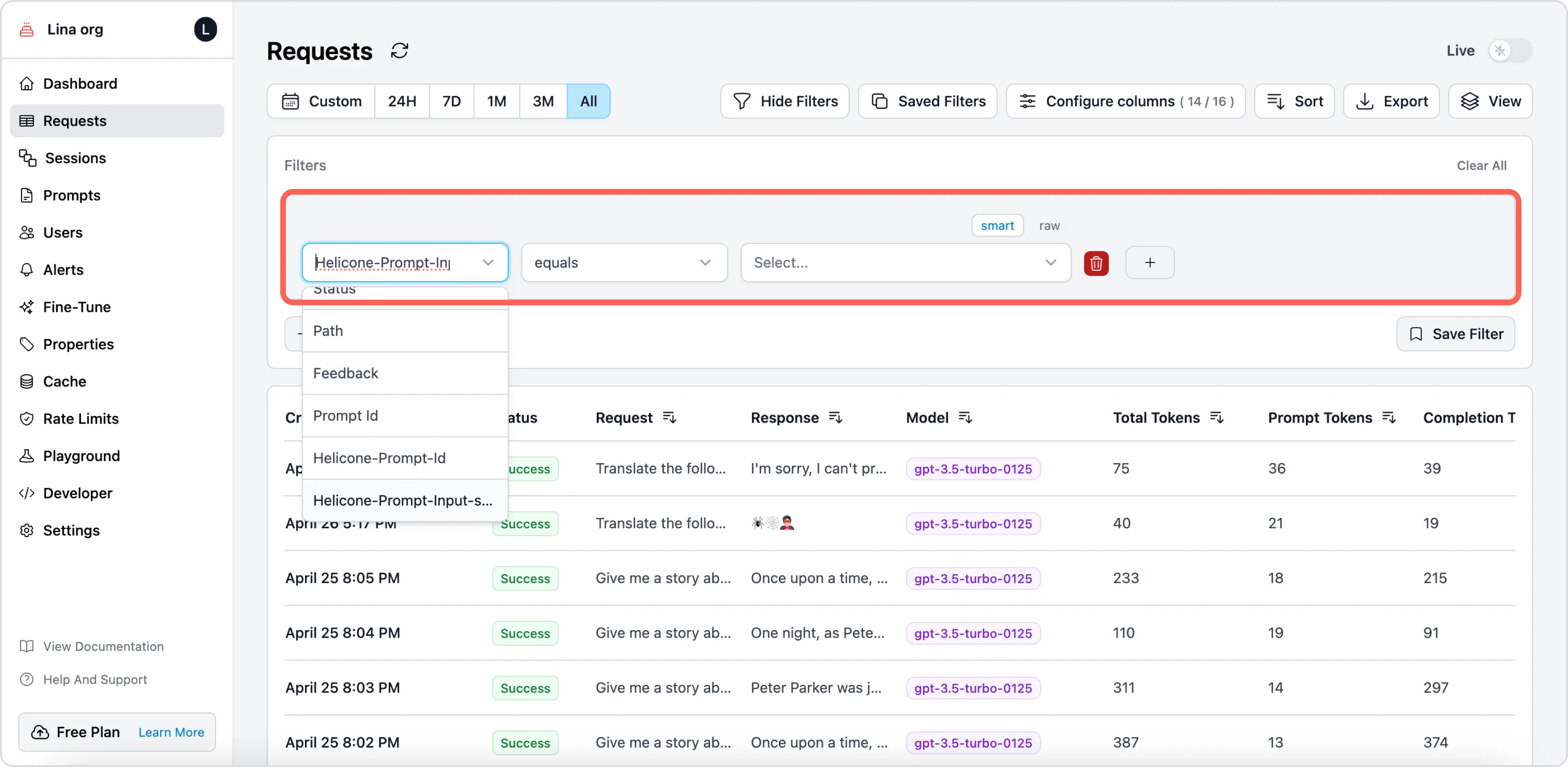
Use case 1: Filter for specific prompt chains on Requests page to analyze costs and latency.
-
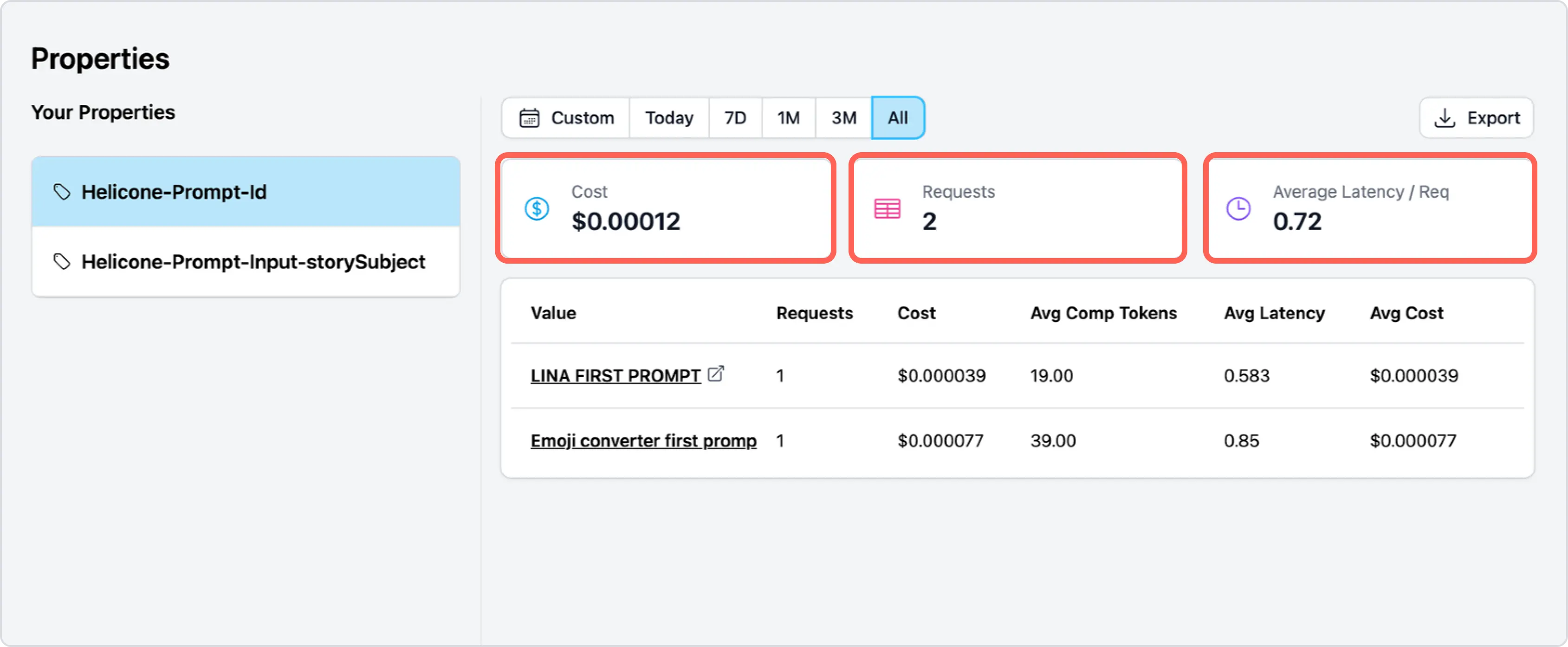
Use case 2: Analyze “unit economics” (e.g., average cost per conversation) on Properties page.
-
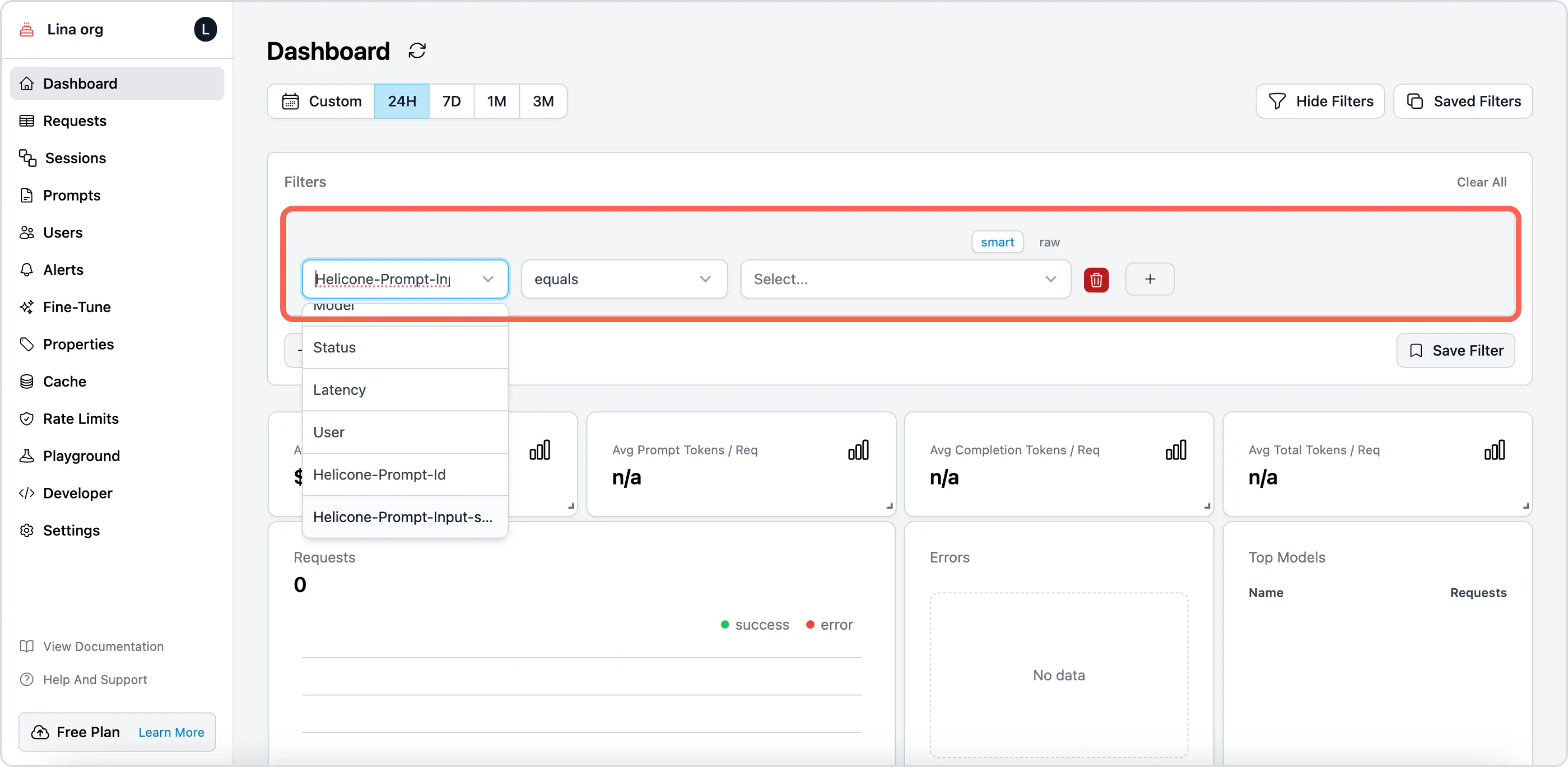
Use case 3: Filter for all requests that meet a criteria on Dashboard page.
Real-life examples
- Segment your requests by app versions to monitor and compare performance.
- Segment your requests by free/paid users to better understand their behaviours and patterns.
- Segment your requests by feature to understand usage pattern and optimize resource allocation.
Additional reading
- Docs: Custom Properties
- Advanced: How to understand your users better and deliver a top-tier experience with Custom Properties
#2: Sessions: debugging complex AI workflows
Helicone’s Sessions feature allows developers to group and visualize multi-step LLM interactions, providing invaluable insights into complex AI workflows. This feature is available on all plans and is currently in beta.
In a nutshell
- You can group related requests for a more holistic analysis.
- You can track request flows across multiple traces.
- You can implement tracing with just three headers.
How it works
-
Add the following three headers to your requests. Here’s the doc on how to enable Sessions.
headers = { "Helicone-Session-Id": session_uuid, # The session id you want to track "Helicone-Session-Path": "/abstract", # The path of the session "Helicone-Session-Name": "Course Plan" # The name of the session } -
Use the Helicone dashboard to visualize and analyze your sessions. For example:
-
Use case 1: Reconstruct conversation flows or multi-stage tasks in the
Chatview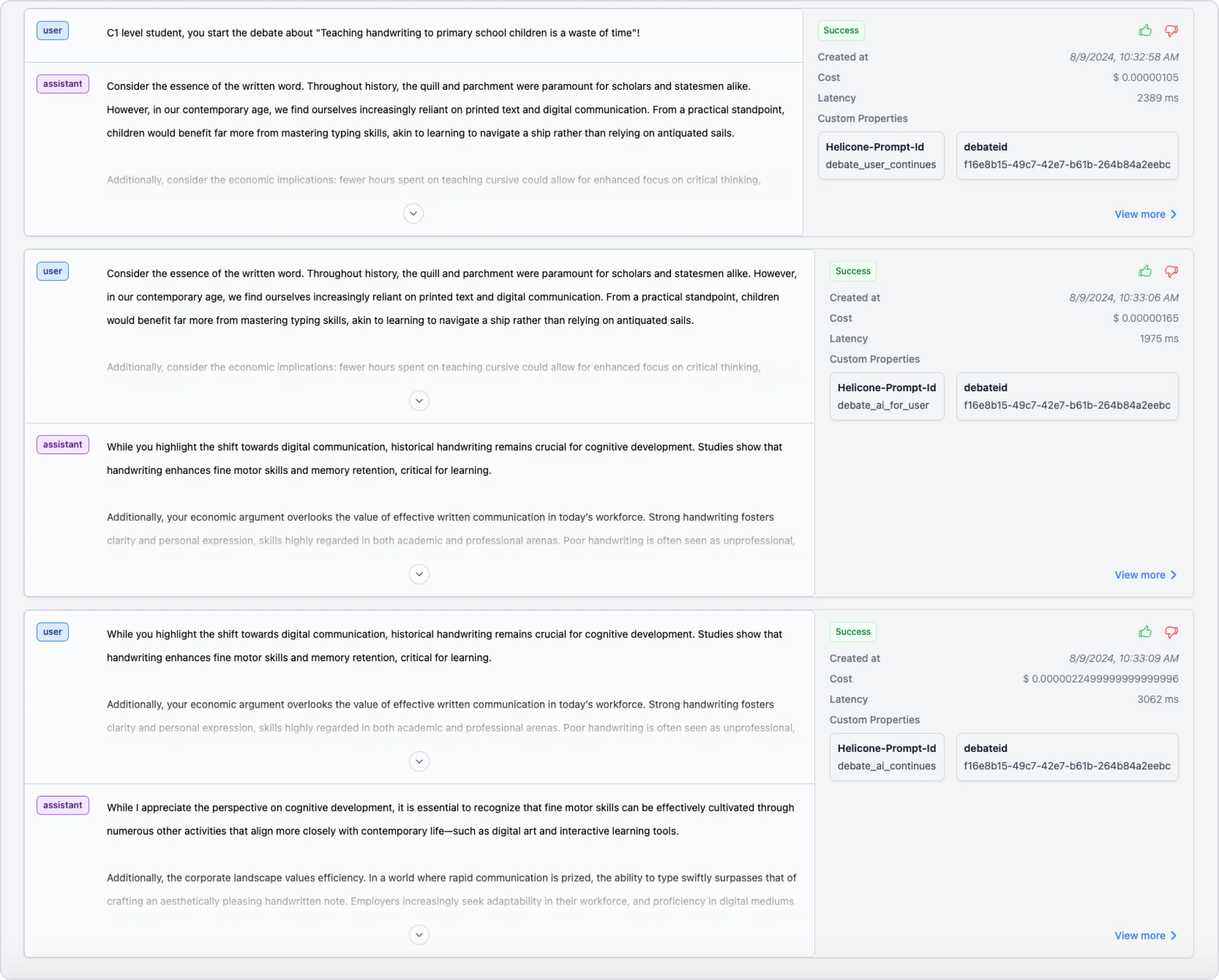
-
Use case 2: Analyze performance across the entire interaction sequence in the
Treeview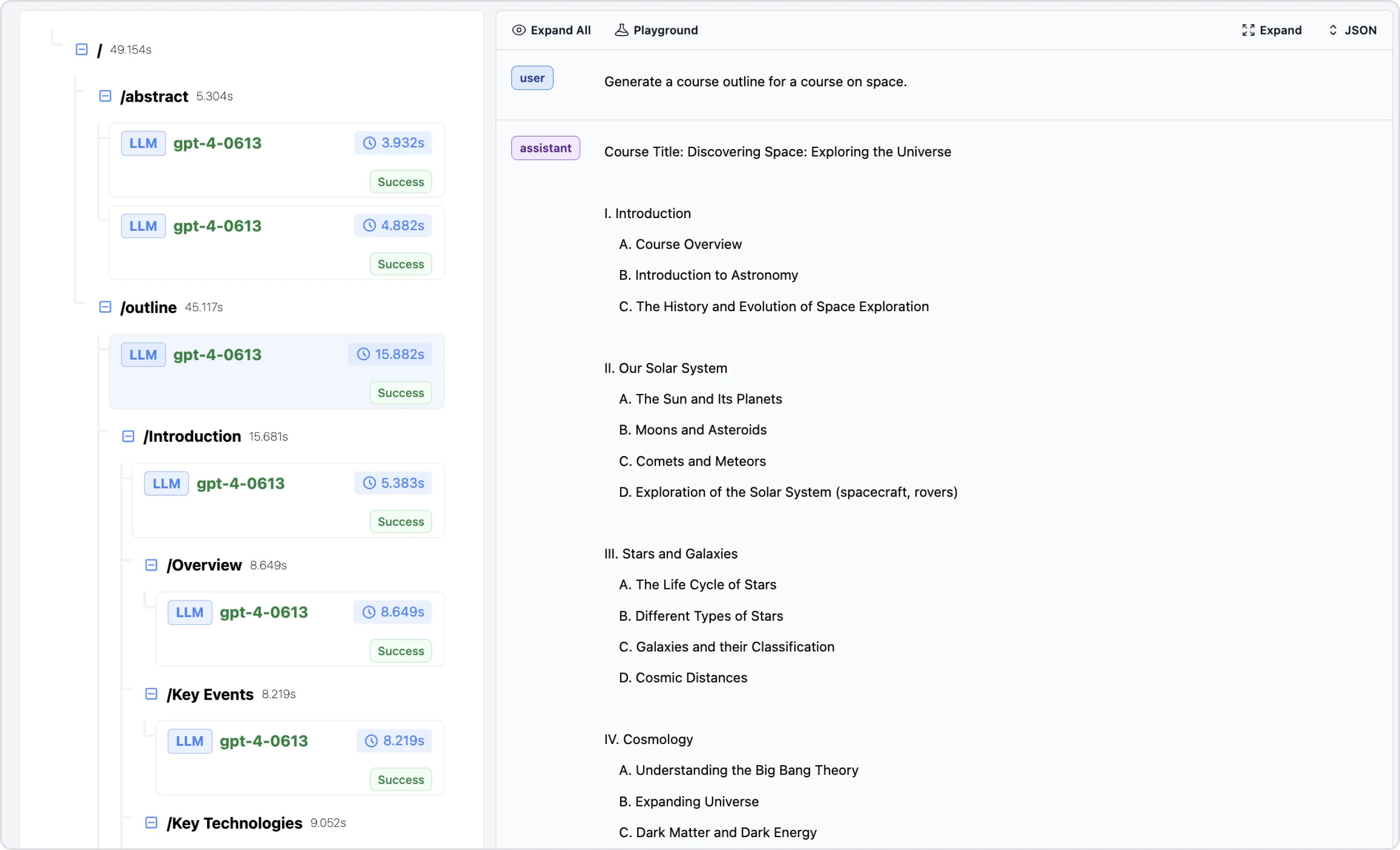
-
Use case 3: Identify bottlenecks in your AI workflows in the
Spanview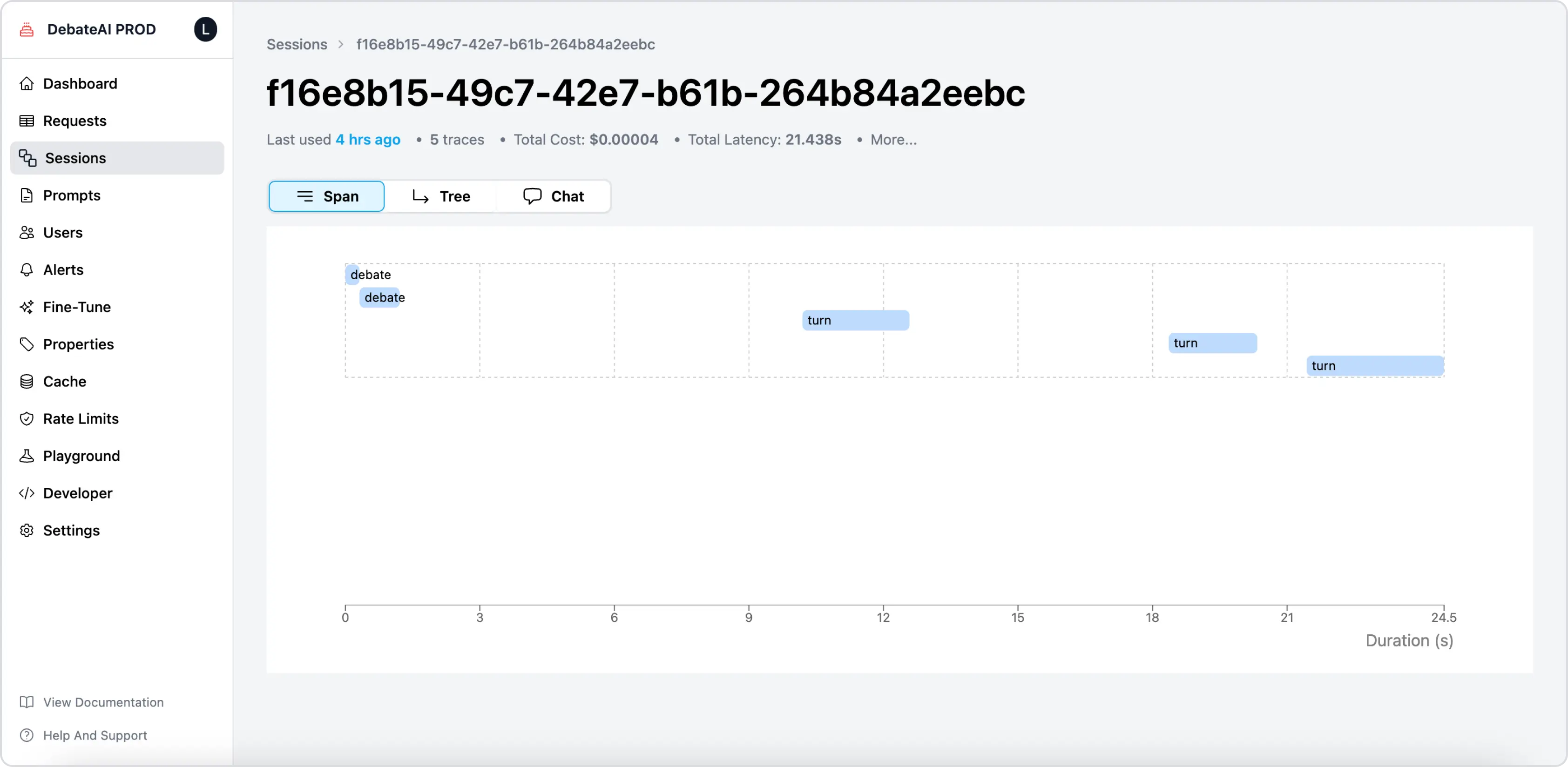
-
Use case 4: Gain deeper insights into user behavior with conversation context.
Real-life example
Imagine creating an AI app that creates a course outline.
const session = randomUUID();
openai.chat.completions.create(
{
messages: [
{
role: "user",
content: "Generate an abstract for a course on space.",
},
],
model: "gpt-4",
},
{
headers: {
"Helicone-Session-Id": session,
"Helicone-Session-Path": "/abstract",
"Helicone-Session-Name": "Course Plan",
},
}
);
This setup allows you to track the entire course creation process, from abstract to detailed lessons, as a single session.
For developers working on applications with complex, multi-step AI interactions, Sessions provides a powerful tool for understanding and optimizing your AI workflows.
Additional reading
- Docs: Sessions
#3: Prompt management: improving and tracking prompts
Helicone’s Prompt Management feature offers developers a powerful tool to version, track, and optimize their AI prompts without disrupting their existing workflow. This feature is available on all plans and is currently in beta.
In a nutshell
- Helicone will automatically version your prompt whenever it’s modified in the codebase.
- You can run experiments using past requests (grouped into a dataset).
- You can test your prompts with Experiments to prevent prompt regressions.
How it works
-
Set up Helicone in proxy mode. Use one of the methods in the Starter Guide.
-
Use the
hpf(Helicone Prompt Format) function to identify input variablesimport { hpf } from "@helicone/prompts"; ... content: hpf`Write a story about ${{ character }}`, -
Assign a unique ID to your prompt using a header. Here’s the doc on Prompt Management & Experiments. For example:
headers: { "Helicone-Prompt-Id": "prompt_story", },
Example implementation
import { hpf } from "@helicone/prompts";
const chatCompletion = await openai.chat.completions.create(
{
messages: [
{
role: "user",
content: hpf`Write a story about ${{ character }}`,
},
],
model: "gpt-3.5-turbo",
},
{
headers: {
"Helicone-Prompt-Id": "prompt_story",
},
}
);
Benefits
- Track prompt iterations over time
- Maintain datasets of inputs and outputs for each prompt version
- Easily run A/B tests on different prompt versions
- Identify and rollback problematic changes quickly
Real-world application
Imagine you are developing a chatbot and want to improve its responses. With prompt management in Helicone, you can:
- Version different phrasings of your prompts
- Test these versions against historical data
- Analyze performance metrics for each version
- Deploy the best-performing prompt to production
The Prompt & Experiment feature is not only for developers to iterate and experiment with prompts, but also enables non-technical team members to participate in prompt design without touching the codebase.
Additional reading
- Docs: Prompts & Experiments
- Choosing a prompt management tool | Helicone
- How to run LLM Prompt Experiment | Helicone
#4: Caching: boosting performance and cutting costs
Helicone’s LLM Caching feature offers developers a powerful way to reduce latency and save costs on LLM calls. By caching responses on the edge, this feature can significantly improve your AI app’s performance.
In a nutshell
- Available on all plans (up to 20 caches per bucket for non-enterprise plans)
- Utilizes Cloudflare Workers for low-latency storage
- Configurable cache duration and bucket sizes
How it works
-
Enable caching with a simple header:
headers = { "Helicone-Cache-Enabled": "true" } -
Customize caching behavior. For detailed description on how to configure the headers, visit the doc.
headers = { "Helicone-Cache-Enabled": "true", "Cache-Control": "max-age=3600", # 1 hour cache "Helicone-Cache-Bucket-Max-Size": "3", "Helicone-Cache-Seed": "user-123" } -
(optional) Extract cache status from response headers:
cache_hit = response.headers.get('Helicone-Cache') cache_bucket_idx = response.headers.get('Helicone-Cache-Bucket-Idx')
Benefits
- Faster response times for common queries
- Reduced load on backend resources
- Lower costs by minimizing redundant LLM calls
- Insights into frequently accessed data
Real-world application
Imagine you’re building a customer support chatbot. With LLM Caching:
- Common questions get instant responses from cache
- You save on API costs for repetitive queries
- Your app maintains consistent responses for similar inputs
- You can analyze cache hits to identify popular topics
Example implementation
client = OpenAI(
api_key="<OPENAI_API_KEY>",
base_url="https://oai.helicone.ai/v1",
default_headers={
"Helicone-Auth": f"Bearer <API_KEY>",
"Helicone-Cache-Enabled": "true",
"Cache-Control": "max-age=2592000",
"Helicone-Cache-Bucket-Max-Size": "3",
}
)
chat_completion_raw = client.chat.completions.with_raw_response.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello world!"}]
)
cache_hit = chat_completion_raw.http_response.headers.get('Helicone-Cache')
print(f"Cache status: {cache_hit}") # Will print "HIT" or "MISS"
LLM Caching provides a faster response time and valuable insights into usage patterns, allowing developers to further refine their AI systems.
Conclusion
If you are an building with AI, LLM observability tools can help you:
- ✅ Improve your AI model output
- ✅ Reduce latency and costs
- ✅ Gain deeper insights into your user interactions
- ✅ Debug AI development workflows
Helicone aims to provide all the essential tools to help you make the right improvements and deliver better AI experiences. Interested in checking out other features? Here’s a list of headers to get you started. Happy optimizing!